"Man is a 'homo discens,' a learning being. People learn as long as they live. Life is inseparably connected with learning." Horst Siebert
discere
From Proto-Italic *diskō, from earlier *dikskō, from Proto-Indo-European *di-dḱ-ské-ti, derived from the root root *deḱ- (“to take”). From the same root as doceō and discipline unrelated to discipulus.
Questio
What did You learn today ?
What was the most important thing You learned this year ?
Implicit learning
Implicit learning is the process of acquiring knowledge or skills unconsciously, without intentional effort or explicit awareness of what is being learned. It typically occurs through repeated exposure to patterns, stimuli, or behaviors, allowing individuals to internalize rules or structures without being able to articulate them directly.
Observation
Observation in the context of learning refers to the process of acquiring knowledge, skills, or behaviors by perceiving the actions of others or the dynamics within an environment. This learning occurs without direct engagement but through experiencing of external stimuli, events, or behaviors.
Proprioceptive Exercise
Keep standing. Close Your eyes. Arms wide apart.
Now try to bring Your hands together so that the whole half-circle movement lasts exactly one minute.
That is, fingers of Your two hands will meet in exactly 60 seconds.
Concentric circle exercise
Let's speak about ways and means how humans observe their environments.
Divide into two groups, group 1 forms the internal circle, group 2 forms the external one.
Two people stand against each other, face to face. After posing and answering a question like:
How do You observe ?
By what sense do You prefer to observe ?
What do You observe ?
members of G1 move to the left and members of G2 move to the right.
Gradually, all members of Group 1 are supposed to speak with each member of Group 2, and vice versa.
Unsupervised learning
Unsupervised learning is a type of machine learning where a model is trained on data without labeled outcomes. The system analyzes and identifies patterns or structures in the data, such as clustering or associations, without explicit guidance on what to look for. It is often used for tasks like anomaly detection, clustering, and dimensionality reduction.
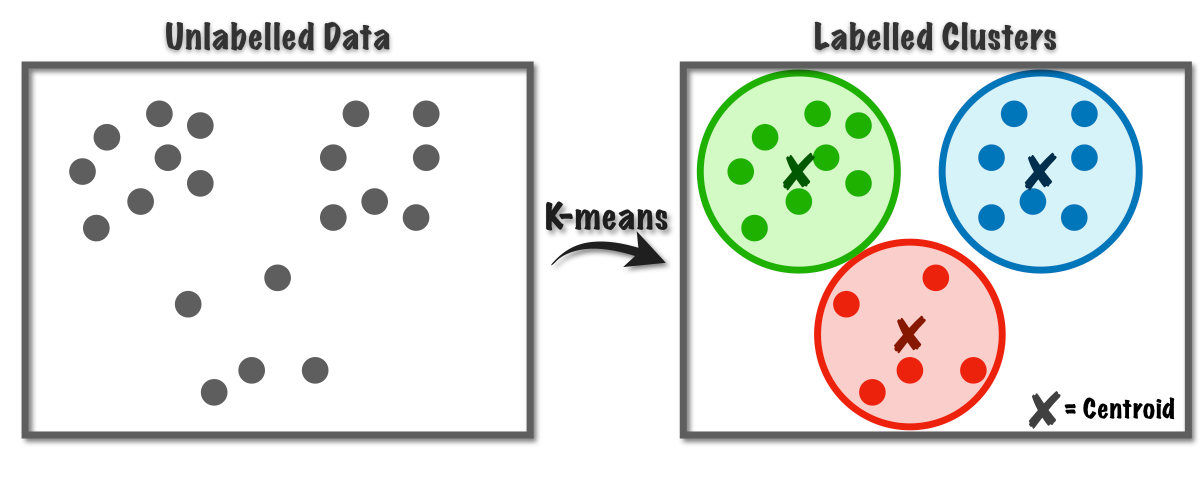
Example of unsupervised learning
DALL-E/GPT4o prompt: Provide black and white illustration of your response regarding unsupervised learning of music tunes into music genre clusters, in style of Gustav Doree
Imagine you have a big collection of music tracks from various genres, but you don’t know the genre of each track. Using unsupervised learning, like a clustering algorithm, you could group these tracks based on their similarities—such as tempo, rhythm, and melody—without telling the algorithm what the genres are. The result might be clusters of songs that are similar, and when you check the groups, you find that most of them correspond to genres like rock, jazz, or classical. The algorithm discovers these patterns or categories on its own, without any prior labels or supervision.
Can You think of other examples of unsupervised learning and/or clustering ?
Clustering
Clustering is a machine learning technique used to group a set of data points into clusters based on their similarity. It is an unsupervised learning method, meaning that the data does not have predefined labels. The goal of clustering is to organize data so that items within the same cluster are more similar to each other than to those in other clusters. Common algorithms include k-means, hierarchical clustering, and DBSCAN.
Features of implicit learning
No direct guidance :: Learner L must identify patterns or relationships from raw input on her own.
Pattern discovery :: Observation often involves recognizing and understanding patterns in the environment, which mirrors what happens in unsupervised learning.
Learning from the environment :: L derives insights from the world or data without external labels or supervision.
Imitation
Imitation in humans, especially in children, is the process of learning by observing and replicating the actions, behaviors, or expressions of others. It is a fundamental mechanism for acquiring social, cognitive, and motor skills, allowing children to mimic gestures, language, or problem-solving techniques. Through imitation, children learn cultural norms, communication patterns, and even complex tasks without explicit instruction. It is crucial for early development, as it helps children integrate into their social environment and build understanding by modeling behaviors they see in parents, peers, and others.
Mirror neurons
Mirror neurons are specialized brain cells that activate both when an individual performs an action and when they observe someone else performing the same action. These neurons were first discovered in primates and are thought to play a key role in understanding the actions and intentions of others, as well as in processes like imitation, learning, and empathy. In humans, mirror neurons are believed to be involved in social cognition, allowing us to simulate and internalize the experiences of others, thus facilitating learning through observation and emotional connection.
Mirror neurons video
1st definition of learning
Learning is building A model of THE world.
Experiential learning
Experiential learning is a process of learning through direct experience, where individuals engage in activities, reflect on their actions, and apply what they’ve learned to new situations. Rather than solely reading or listening, learners actively participate, often experimenting, making mistakes, and adapting.
Trial
In learning and problem-solving, a "trial" is a single attempt or effort to reach a goal or find a solution. Each trial involves testing an idea or making a change, then observing the result. If the trial doesn’t succeed, adjustments are made based on what was learned, and a new trial begins. This process, called "trial and error," continues until the desired outcome is achieved. Trials are key in learning because they allow us to explore, adapt, and improve with each attempt, reducing mistakes and moving closer to success over time.
Error
In learning and problem-solving, an "error" is the difference between what we aimed to achieve and the actual result. It shows how far we are from the desired outcome and helps us understand what needs adjusting. Errors aren’t failures; they’re valuable feedback, guiding us to make improvements in each new attempt. By identifying and reducing errors through practice and adjustments, we gradually get closer to the goal. In this way, errors are essential to learning, as they highlight what doesn’t work and point us toward what might.
sed perservere...
"Errare humanum est, sed in errare perseverare diabolicum" (Seneca, 62 A.D.)
To err is human, to stay in error diabolical.
Two types of errors
Essentially, there are two type of errors:
the "bad" errors (often happen only once)
the "innocent" (unpleasant but useful minor misstep)
Turn to Your neighbour, discuss the question "what was the worst error (e.g. the biggest fuckup) You ever did/caused in Your life". After 5 minutes, each couple will be asked to present at least one such error to the plenum.
Repetition
In learning, skill-building, and habit formation, repetition is the process of repeatedly practicing or performing a task. This continuous repetition reinforces memory, builds familiarity, and over time, transforms skills into habits or reflexes, making actions more automatic and effortless. Through repetition, connections in the brain are strengthened, allowing tasks to be completed with less conscious effort.
Questio
What action / activity do You repeat most often ?
repetitio.digital.udk-berlin.de
Game
Game provides a closed system whereby we are allowed to commit errors (& learn from them) without major consequences for real life.
What is Your most favorite game / way of playing ?
Any game You would like to bring & play with Your colleagues during the Congress ?
Homo ludens
Homo ludens, or "the playing human," is a concept introduced by cultural theorist Johan Huizinga, highlighting play as a fundamental aspect of human culture. This view proposes that play is not only a leisure activity but a primary driver of creativity, learning, and social development. In play, humans explore rules, roles, and freedom, creating a space for innovation, ritual, and expression. Huizinga argues that play shapes not just individual behavior but entire cultures, influencing arts, law, and societal norms. Homo ludens thus redefines humanity as inherently playful, suggesting that play is as crucial to society as work or reason.
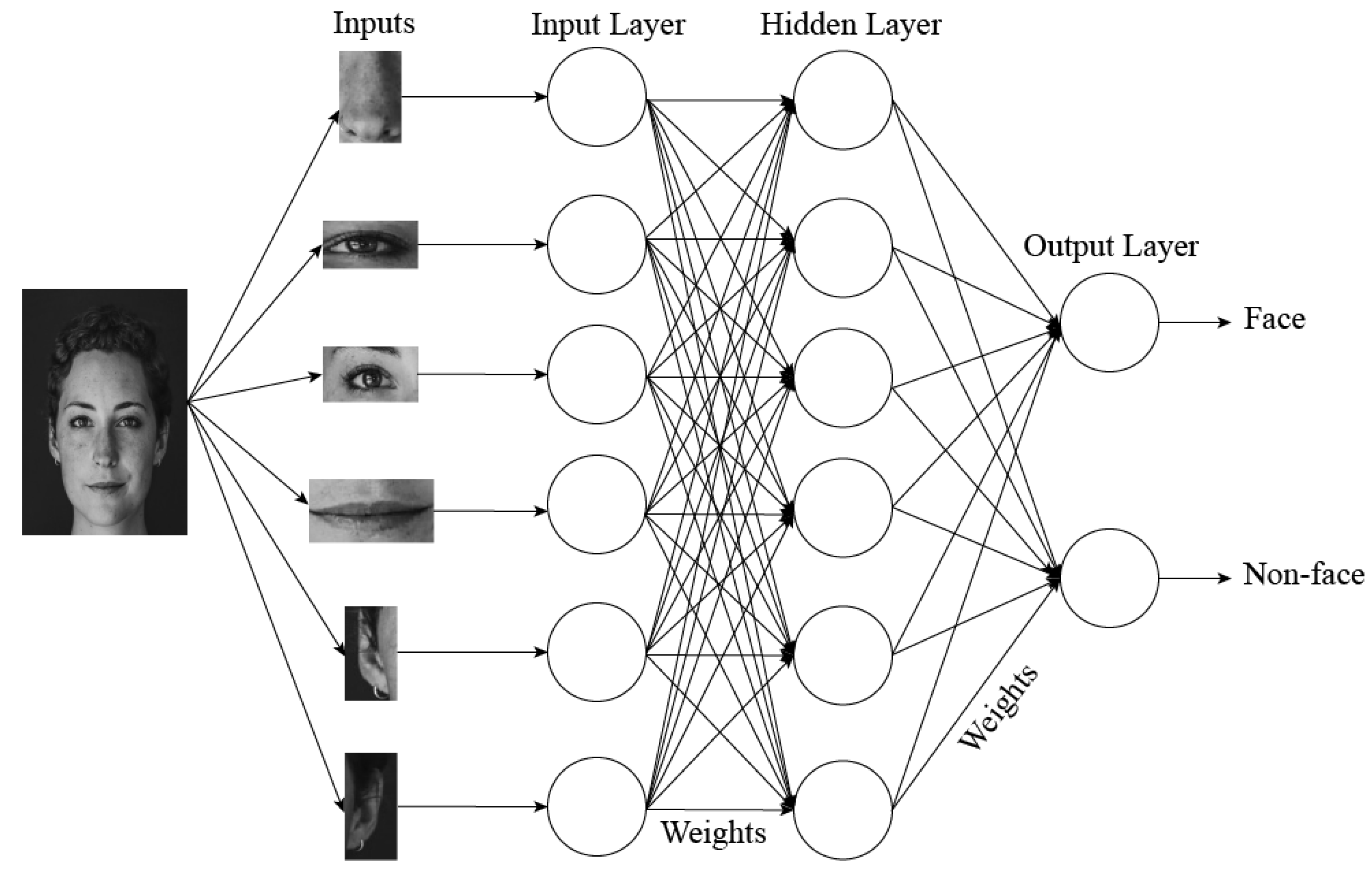
Supervised learning
Supervised learning is a type of machine learning where a model is trained on labeled data to learn the mapping between input features and corresponding outputs. The goal is to enable the model to make accurate predictions or classifications on unseen data by minimizing the error between its predictions and the true labels. Common tasks include regression (predicting continuous values) and classification (assigning categories). Supervised learning relies on a training dataset with known inputs and outputs and evaluates performance using a separate test dataset. Examples include spam email detection, image recognition, and speech-to-text systems.
Testing
In supervised machine learning, *testing* (or *inference*) is the process of evaluating a trained model's ability to make accurate predictions on new, unseen data. During this phase, the model is given data points with *features* (inputs like size or color) but without the labels it was trained on. The model uses the patterns it learned during training to predict the labels for this data. The results are then compared to the actual labels (if available) to measure the model's performance using metrics like accuracy or precision. Inference is the final application of the model to make real-world predictions.
Supervised learning & Human learning
Supervised learning parallels human learning through its reliance on guidance from labeled examples, similar to how humans learn with feedback. For instance, when a child learns to identify objects, they receive input (the object) and a corresponding label (e.g., "dog" or "apple") from a teacher or parent. Mistakes are corrected, reinforcing the connection between input and label, much like how supervised learning algorithms adjust their predictions based on errors.
Categorization
Categorization is a fundamental human cognitive process where we group objects, ideas, or experiences based on shared characteristics.
Classifiers
A classifier in machine learning is a model or algorithm designed to categorize data into predefined groups or labels. It takes input data, analyzes its features, and assigns it to a specific class based on learned patterns from training data. For example, a classifier might identify whether an email is spam or not spam, or recognize handwritten digits. Classifiers are essential in supervised learning tasks and operate by minimizing errors in predictions through training on labeled datasets. Common types include neural networks, support vector machines, decision trees etc.
Decision Trees
A Decision Tree is a visual and intuitive machine learning method that makes decisions by asking questions about the data. It works like a flowchart, starting with a question at the top and branching out based on answers. These questions are not just yes/no, but can also be comparisons, like "Is the age greater than 18?" or "Is the temperature below 30°C?" Each split is chosen using a quantitative measure, such as information gain or Gini impurity, to find the best threshold for separating the data.
Exercicio: AI Unplugged 1
You will form teams of two and use the training data to develop criteria for distinguishing biting from non-biting monkeys. These must be clearly noted so that they can be applied to new examples by another team afterwards. A possibility to record the criteria is a decision tree. It should be the goal that the existence or absence of a particular feature permits a clear assignment to one of the groups. The use of decision trees is optional, alternatively, it is also possible to explicitly write down decision rules.
At the end ofthe training phase, the criteria formulated are exchanged with another team. Now, the students are shown the pictures of the remaining monkeys (test data) one after the other. For each image, the teams decide whether the monkey will bite or not using the scheme of rules developed by their classmates...
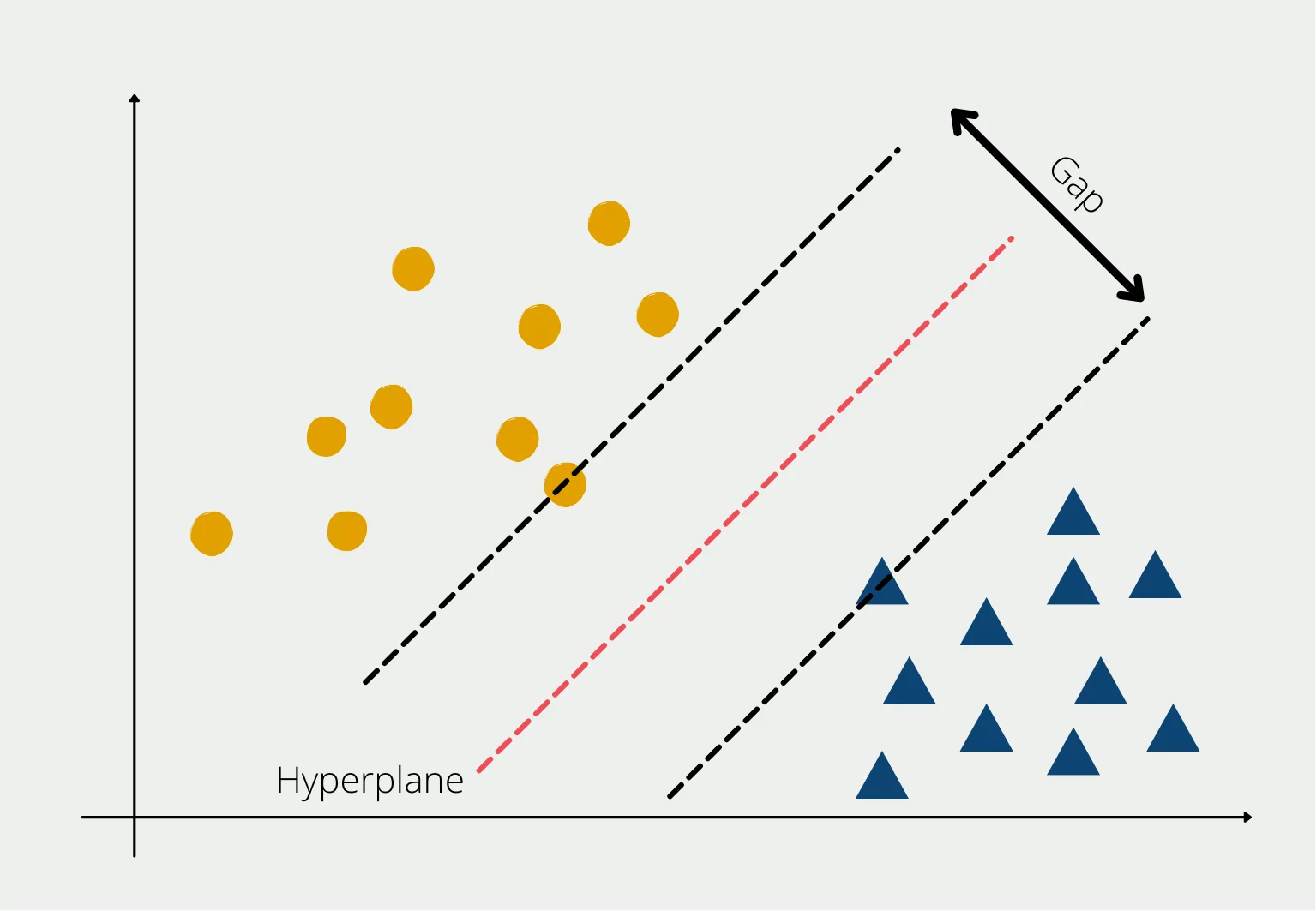
Support Vector Machines
A Support Vector Machine (SVM) is a machine learning method that helps divide data into categories. Imagine drawing a line (or boundary) on a graph to separate different groups of points, like cats and dogs. SVM finds the best line that keeps the groups as far apart as possible. For trickier data, it can use special math (called kernels) to draw curves or work in higher dimensions.
Training
In supervised machine learning, training is the process of teaching a model, like a classifier, to make accurate predictions by learning patterns from labeled data. Each data point in the training set includes features (characteristics or inputs that describe the data, like size or color) and a corresponding label (the correct output or category). The model uses this data to adjust its internal parameters, minimizing the error between its predictions and the actual labels. This is done through algorithms like gradient descent. The goal is to generalize from the training data, enabling the classifier to make accurate predictions on new, unseen data.
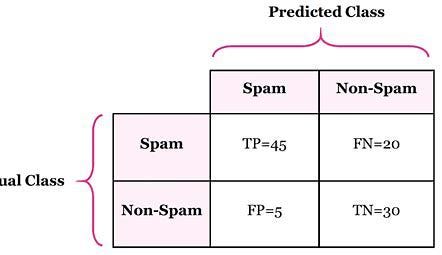
Evaluation
Binary classifiers are evaluated by comparing their predictions to the actual outcomes using a confusion matrix. This is a table with four categories: True Positives (TP), where the classifier correctly predicts a positive outcome; True Negatives (TN), where it correctly predicts a negative outcome; False Positives (FP), where it wrongly predicts a positive; and False Negatives (FN), where it misses a positive case. Metrics like accuracy (overall correctness), precision (focus on positives), and recall (how well positives are found) are calculated from this matrix, helping to assess the classifier’s performance.
Validating
In supervised machine learning, *validating* is the process of fine-tuning and assessing a model's performance during training to ensure it generalizes well to unseen data. Unlike testing, validation occurs on a separate *validation set*, distinct from both training and testing data. The model uses the *features* of this set to make predictions, which are compared to the actual labels to calculate metrics like accuracy or loss. This helps monitor overfitting or underfitting and guides adjustments to model parameters or hyperparameters (e.g., learning rate or regularization). Validation ensures the classifier is optimized before its final evaluation on the test set.
Machine Learning
Machine Learning
Reinforcement learning
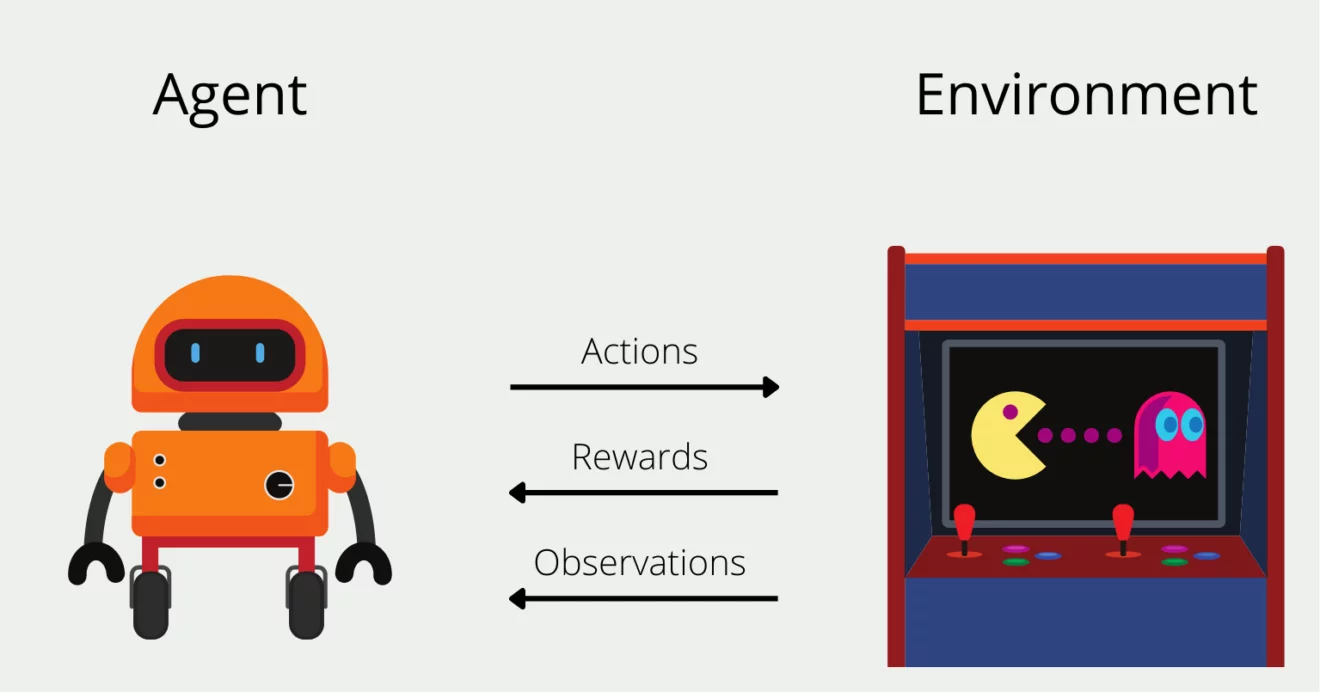
Reinforcement learning (RL) is a machine learning paradigm where an agent learns to make decisions by interacting with an environment. Instead of being told what to do, the agent takes actions and receives feedback in the form of rewards or penalties. The goal is to maximize cumulative rewards over time by discovering an optimal strategy, known as a policy. RL is inspired by trial-and-error learning in humans and animals, where behavior improves through experience. It’s particularly useful for tasks with sequential decision-making, such as robotics, game playing, and autonomous systems, where actions impact not only immediate rewards but also future outcomes.
Supervised learning resembles a structured classroom environment, where explicit feedback is given for each example (e.g., a teacher correcting a student's answers). In contrast, reinforcement learning mirrors experiential learning, where feedback comes as rewards or penalties after actions, guiding behavior toward long-term goals. For instance, a child learning to ride a bike might fall (penalty) or stay balanced (reward), gradually improving through trial and error.
Conditioning
Conditioning is a learning process where an individual forms associations between stimuli or behaviors and their outcomes. It can be divided into two main types:
Classical Conditioning: Involves pairing a neutral stimulus with a meaningful one to elicit a similar response (e.g., Pavlov’s dogs salivating at the sound of a bell).
Operant Conditioning: Involves learning through rewards or punishments, where behaviors are strengthened or weakened based on their consequences (e.g., Thorndike’s Law of Effect).
Law of Effect
When satisfaction follows association, it is more likely to be repeated.
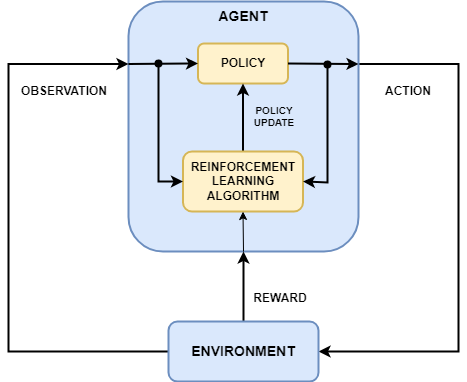
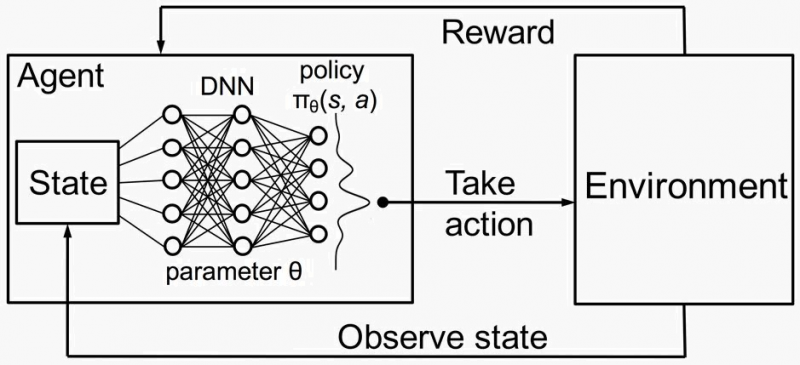
Agent-Environment Framework
In machines, reinforcement learning (RL) is implemented using an agent-environment framework. The agent interacts with an environment by taking actions based on a policy (a strategy for decision-making). The environment provides feedback in the form of rewards or penalties, guiding the agent to improve its actions. Key components include a reward function to evaluate outcomes, a value function to estimate long-term benefits of actions, and exploration strategies to balance learning new behaviors versus exploiting known rewards.
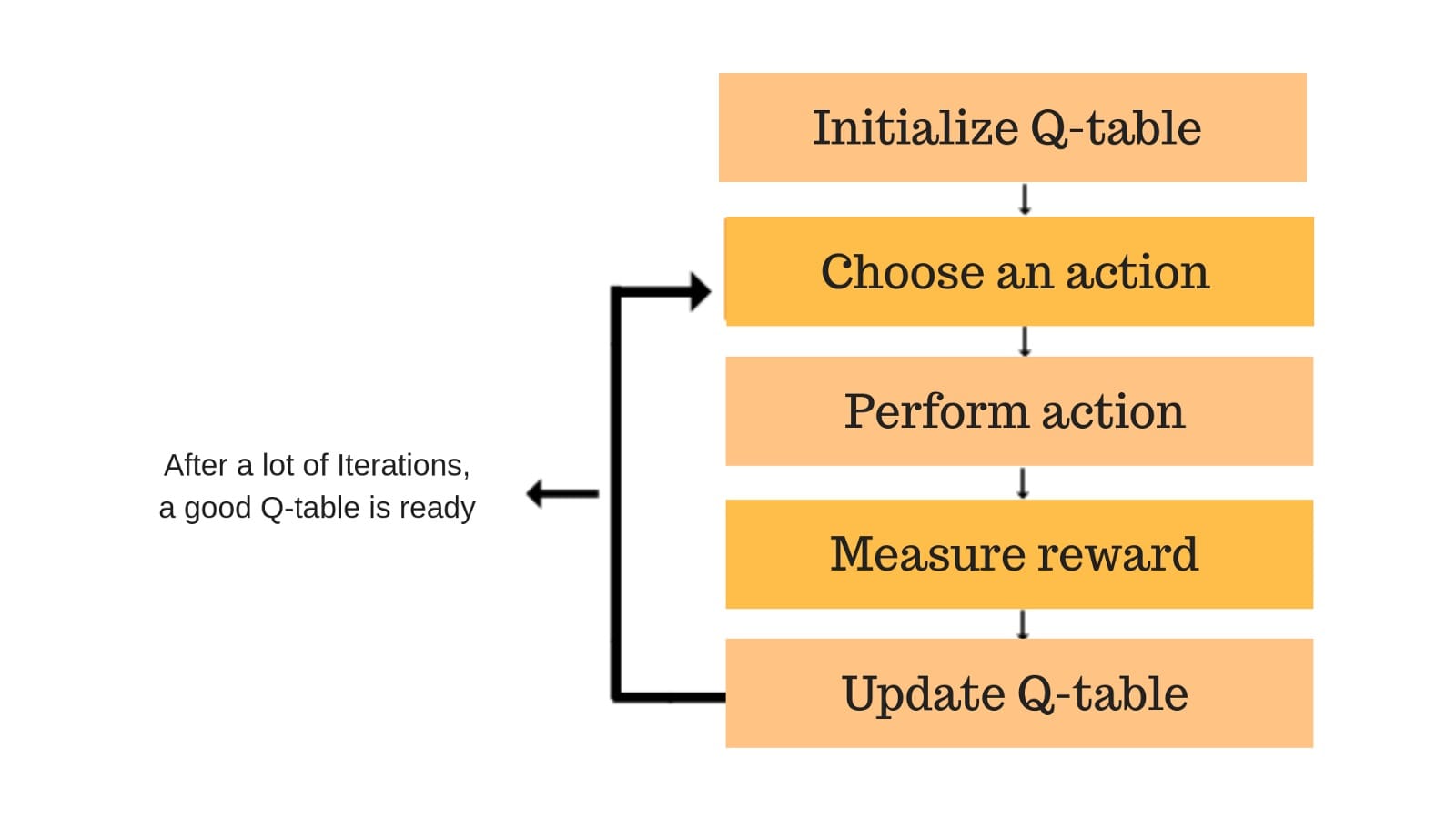
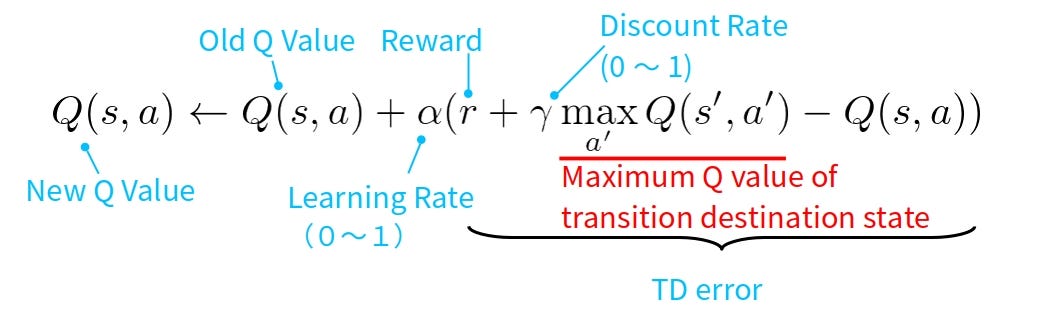
Q-learning
Q-learning is a model-free reinforcement learning algorithm that enables an agent to learn an optimal policy for decision-making. It works by estimating the Q-values (action-value function), which represent the expected cumulative reward for taking an action in a given state and following the best future actions. The agent updates Q-values iteratively using the formula:
Deep reinforcement learning
DRL is a type of machine learning where an agent learns to make decisions by trial and error, guided by rewards or penalties, using deep neural networks. Unlike traditional methods, which struggle with complex environments, DRL allows machines to learn directly from raw data, like images or game screens. The neural network helps the agent recognize patterns and improve its decisions over time. DRL has achieved impressive results in tasks like playing video games (e.g., Atari, AlphaGo), controlling robots, and developing self-driving cars, making it a powerful tool for solving real-world problems involving sequential decision-making
AlphaGO
In 2016, AlphaGo stunned the world by defeating Go champion Lee Sedol, proving that AI could outthink humans in one of the most complex games ever. Using deep learning and Monte Carlo Tree Search, it played moves no human dared—showcasing creativity, brilliance, and the unsettling realization that humanity might be screwed.
Hebb's Law
"Cells that fire together, wire together."
Explanation
When two neurons in the brain activate at the same time repeatedly, their connection strengthens. This makes it easier and more probable for one to trigger the other in the future.
Art Analogy
Imagine practicing a particular brushstroke over and over. Each time, your hand and brain coordinate, and with practice, the connection becomes stronger and the stroke becomes smoother. Similarly, Hebb’s law underpins how practice makes perfect.
Social learning
Social learning is "a process in which individuals learn by observing the behaviors of others, imitating them, and experiencing the consequences of these actions." (Bandura, 1977)
Social Learning Theory
Albert Bandura’s Social Learning Theory (1977) revolutionized psychology by emphasizing that learning occurs in a social context through observation, imitation, and modeling. He argued that individuals do not solely learn through direct reinforcement (as behaviorism suggests) but also by observing others, processing information cognitively, and making choices based on expected outcomes.
Reciprocal Determinism
Behavior, cognition, and the environment interact in a dynamic way.
Example: A student’s shyness (personal factor) affects classroom participation (behavior), which in turn shapes peer interactions (environment).
Vicarious Reinforcement
Vicarious means experiencing something indirectly, through someone else, rather than firsthand. It comes from the Latin vicarius, meaning "substitute" or "acting in place of another."
Individuals learn by observing others being rewarded or punished for a behavior.
Example: A student is more likely to participate in class if they see a peer receiving praise for doing so.
Four Key Processes of Social Learning
Attention: The learner must focus on the model’s behavior.
Retention: The behavior must be stored in memory for later retrieval.
Reproduction: The learner must have the ability to replicate the behavior.
Motivation: There must be an incentive to imitate the behavior (e.g., rewards, social acceptance).
Observational Learning
Learning happens by watching others and imitating their behavior, even without direct reinforcement.
Example: A child learns aggression by observing an aggressive adult (c.f. "The Bobo Doll Experiment")
Peer learning
Peer learning
Four pillars of learning
Active engagement:::Attention:::Error Feedback:::Consolidation